
試そうと思った理由
Youtube動画などで男性のVTuberが女性の声をこもらず滑らかに出していたので私も試したくなったからです。
またPytorchを使ってAI学習でモデルが作られて動作している点がStable DiffusionやAnimatediffを試し、音声も試せるならやってみたいと思ったからです。
RVC(Retrieval-based-Voice-Conversion)
中国発のAIボイスチェンジャーで、2023年12月現在では一番高スペックな機能を持ちます。ただし開発元は不明なため、それなりにセキュリティもしくは著作権上のリスクがあるのがデメリットです。
 島十練子(Tonerico_JP)
島十練子(Tonerico_JP)また個人的に利用してみてのメリットは音声に不自然さはあまりないものの、デメリットは不明瞭なインプットであると間違った発音をしてしまう可能性があることです。例えば「あ」と発音しているつもりでも「お」と出力されてしまう場合があります。
日本語が上手い外国人の発音にそっくりな感じもします。
ただ性転換の発音はクリアに対応していたような気がします。
このRVCを使用するには学習済みの音声データを使う方法と、自ら学習させてRVCの音声データを作る方法の2種類があるようです。
ボイス利用について著作権に触れないかどうかは各個人でボイスごとに確認する必要があります。
ただしBoothでフリーで入手できるものもあり、ただ声を変えたい目的で個人でアフィリエイト目的でYoutube動画上げて利用する程度ならクレジット表記するだけで良いものもあるので法人や個人商品コンテンツ化の一部として使うのでない限りは比較的許容されているものも少なくないようです。
リアルタイムボイスチェンジャー
以下は学習済みのモデルを専ら利用する目的のアプリになります。
入手先:https://github.com/w-okada/voice-changer
上のリンクからv.1.5.3.17bのmacの一行目のlink先をクリックします。

その後下のリストの上から3行目のMMVCServerSIO_mac_onnxcpu-nocuda_v.1.5.3.17bをダウンロードします。
アプリはダウンロードしたら自分のアカウントの直下にフォルダごと移動させましょう。そして、startHttp.commandをControlクリックで「開く」を選んで起動させます。
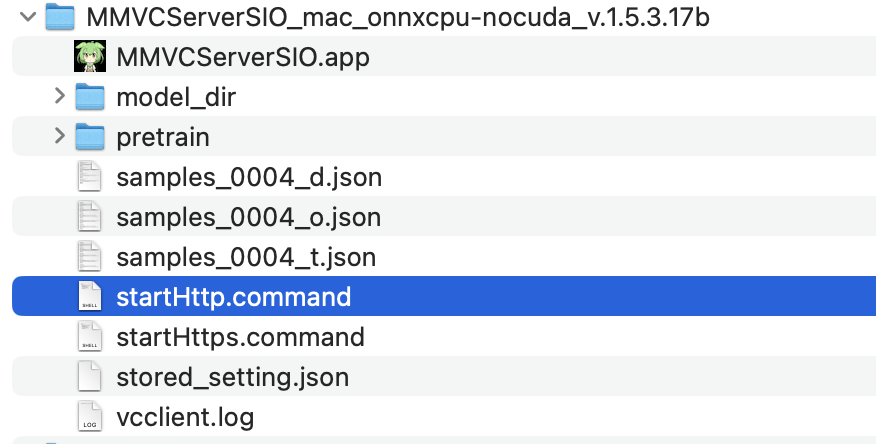
最初だけはStable Diffusionと同じようにインストールが長いため時間がかかります。
VB-Audio Virtual Cableも必要になるのでまだインストールしていない方は先にインストールしておきましょう。
inputはオーディオインターフェイスを指定し、outputはVB-Cableを指定します。
serverを選ぶ方が遅延が少なくなるそうですが、Mac M1で試した感じだとclientでしかオーディオインターフェイスを認識していなかったため私はclientを選んでいます。
monitorは遅延を確認するために使います。ただ口コミによれば遅延があるため、まだリアルタイム変換のライバー活動には向かずレコーディング動画向け止まりだそうです。
CHUNKは遅延のこともあるので実用レベルで200から500が良いようです。レコーディングの場合はマックスにした方が綺麗な音質になります。
男性→女性になる場合はTUNEを12
女性→男性になる場合はTUNEを-12にすると良いようです。
その他は特にいじらなくても良さそうです。
その後右上のeditから学習済みファイルを取り込むことも可能です。
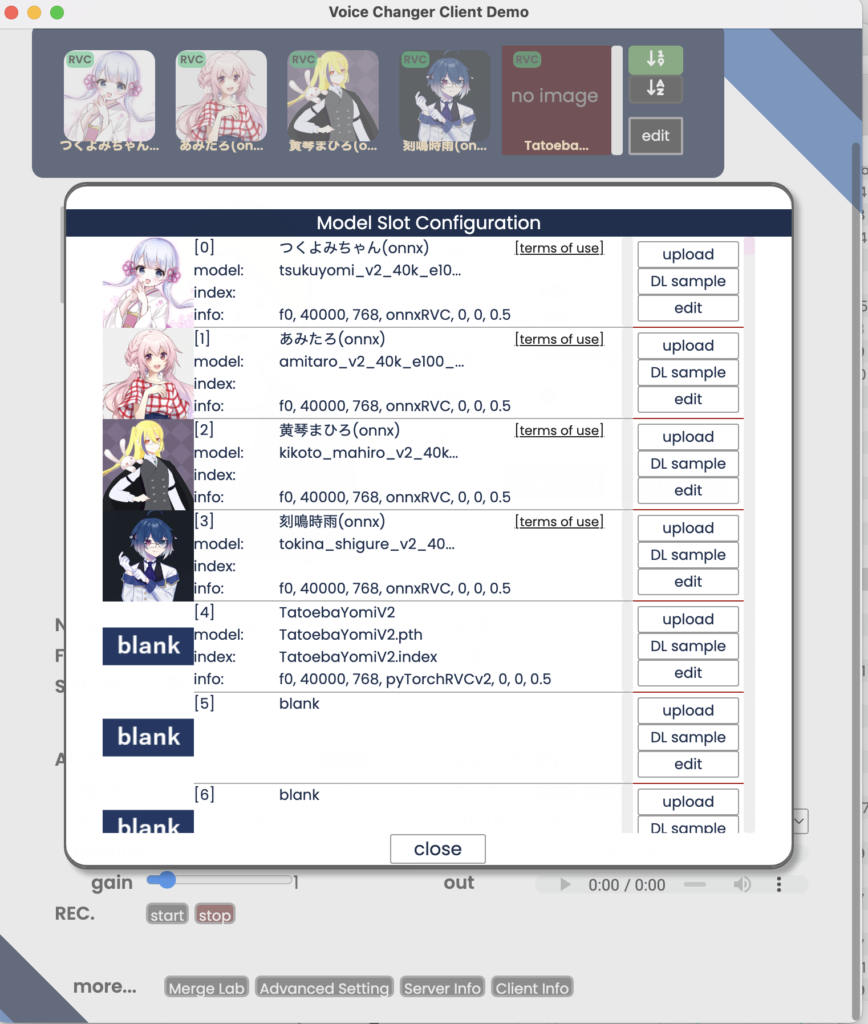
boothで無料でダウンロードしたmodelのpthファイルをmodelに選び、indexはindexファイルを割り当てれば良いようです。
Zoomで使う方法
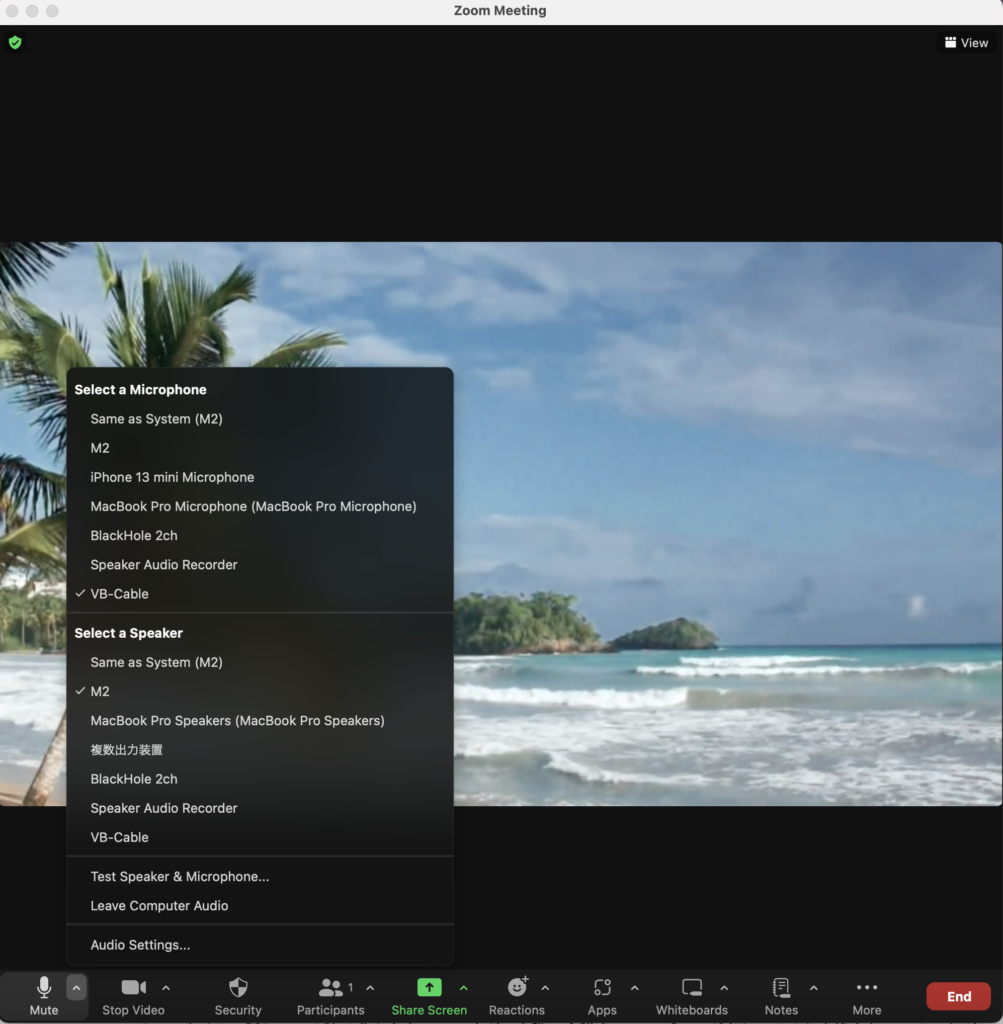
マイク設定をVB-Cableを選び、スピーカーはオーディオインターフェイスもしくはヘッドセット/イヤホンを選びます。
リアルタイムで話している時は分からないのですが、実際に会議をレコーディングをしてみると変換されていることが分かりました。なおレコーディングは会議を終えた後でMeetingsタブのRecordedところに出力されているのを確認できます。
ただどういうわけか自分が現実に発声している声がリアルタイムや遅延ストリーミングでも聞けないので不安になるんです。
島十練子(Tonerico_JP)声のリアルタイム変換するにはまだタイミング遅延が気になります。なので個人的にはまだvoidol3の方がまだ安心して使えるかなと思いました。
同性間の声化粧程度ならそこそこに綺麗な音声かなと思います。
また遅延も少なく変換後の声もストリーミングさせて確認しながら使うこともできるから安心なんです。
(ただしスマホ版のvoidolは完全実用目的ではない完全なおもちゃなのでPC版のつもりで購入すると後悔すると思います。)
ただし5分か10分でボイスチェンジャーが機能しなくなることがあるため再起動の必要はあります。
また購入前にお試し無料版でご自分の環境で動作確認を行うこともできます。
またボイスモデルも音声もこちらから実際に聴いて確認することもできます。
あとこの冒頭で挨拶で話している声はvoidol2のボイスチェンジ後のものになります。

このセットはボイスが女性と男性の声が合計最初から13種類バンドルされています。
○サンプリング周波数: 44100Hz ビット数: 16bit
○処理遅延: 70ms 以内(ASIOドライバー使用時)
Skype
(自分で部屋を作って試すことはできない設定なのでまた機会ある時に試しておきます。)
Google meetで使う場合
録画そのものがプレミアムプランなので試せていませんがおそらくZoomと同じなのではないかと思います。
RVC WebUI 学習のさせ方
音声データを学習する場合はRVC WebUIを使います。
まずこのアプリはmps対応であるためMac M1(Apple Silicon)でそれなりに使えそうです。
もしも以下がインストールされていない場合は別にインストールする必要があります。homebrewを使えばインストール出来ると思います。Stable Diffusionのところでも書きましたので参考にしてみてください。
- python
- ffmpeg
- git
その後
git clone https://github.com/ddPn08/rvc-webui.gitrvc-webui/models/checkpoints
このディレクトリに音声学習済みモデルに相当するpthとindexファイルを入れます。
その後
%cd rvc-webui
%./webui.shこれだけで仮想環境を自動で構築してくれてアプリ起動します。
その後以下まで表示されたらブラウザのURL欄にhttp://127.0.0.1:7860を入力してください。
Running on local URL: http://127.0.0.1:7860そうすると立ち上がったアプリが見えるようになります。
modelのところで学習済みのボイスファイルを選択すると動作させることができるようになります。
まずこのアプリのInferenceタブではあらかじめwavのボイスを用意して変換(ボイスチェンジ)された音声ファイルを出力入手するものになります。
「Infer」ボタンを押すと音声変換処理が開始されます。
その後変換された音声データは「Out folder」で指定したフォルダーに出力されます。(指定しなければ/rvc-wevui/outputs/)
ただしこのアプリの一番の目的は学習モデルを作成することなので、Trainingタブに切り替えてください。
ここでは声素材を以下からお借りして利用するものとします。利用する方は規約をよく読んで順守するようお願いします。
入手先:あみたろの声素材工房さん
dataset globのところを/Users/(あなたのアカウント名)/amitarovoice_20230207_01/**/*.wavを入力します。
(上の/は半角に変更してください。)
音声はWAVE形式、PCM 44,100 kHz/ 16Bit/モノラルで保存されています。
(ほんの数個だけ22kHz)
Pre trained generator pathには学習させる声素材と同じ形式の学習済声データをダウンロードしてきて入れる必要があります。デフォでも一応入っていますが最低限スペックです。Using phone embedderをhubert-japanese-baseにする必要もあります。
学習させるときは右下のTrainボタンを押します。
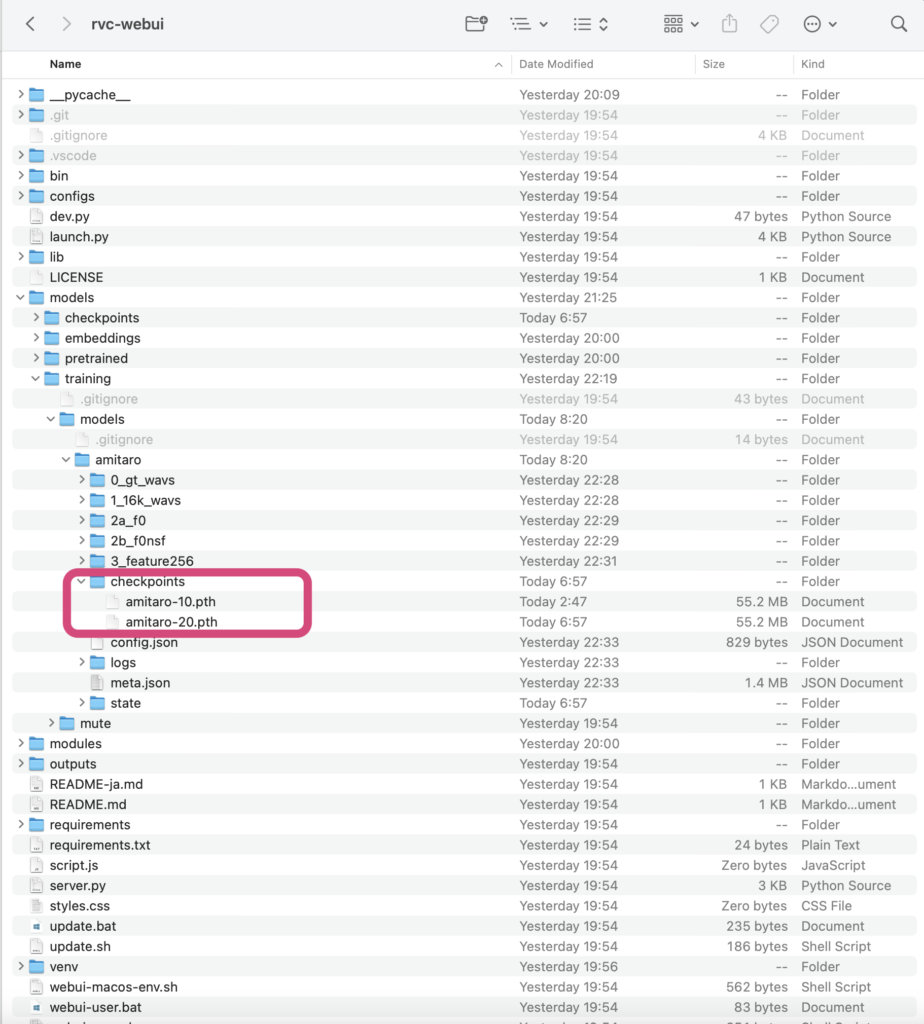
そして5時間ほどで上のような学習済pthファイルが生成されました。
それをstartHttp.commandを起動して編集(Edit)画面から読み込みます。Indexファイルは生成されていないので今回は使いませんでしたが最後まで学習は動作しているようです。
島十練子(Tonerico_JP)何もいじらず音声出力してみたら、日本語の入力に対して出力は日本語ではない言語の音声が出来上がっていました。warningなどのエラーが出ていたことが原因かもしれませんし、学習量がまだ不十分なのかもしれません。
MMVC(Real Time Many to Many Voice Conversion)
一方でMMVCの開発元は日本人の天王洲アイル氏です。RVCはAI学習で変換先の音声データのみで動くのに対し、MMVCはディープラーニングであり、変換先の音声データと自分の声を録音したデータの両方が必要で学習コストが高いばかりでなく重くなりがちです。またデメリットとして学習時間もMMVCはRVCより長く、ボイチェン感が残ると言われています。
このディレクトリに音声学習済みモデルに相当するpthとindexファイルを入れます。
ここの部分がわからなかったのですがどうやるのですか?
初コメントどうも有難うございます。
Macの場合、ターミナルを開いて特にディレクトリ移動など何もしていなければ ダウンロードすると以下のようなディレクトリ構造になるのでFinderでそのままその場所にアクセスして移動させたいディレクトリフォルダと移動前のディレクトリを開くためのFinderをもう一つ開いてドラッグ&ドロップで引っ越すのが楽だと思いますね。
/Users/(アカウント名)/rvc-webui/models/checkpoints